
Introduction
Data Scientists is one of the most exciting professions of the 21st century. Anyone in data science already knows that being a data scientist is essentially having a job as a detective. Many even consider the role to be the sexiest role of modern times.
In this data-driven era, a chunk of data is produced from multifarious devices. A plethora of statistics has claimed that 2.5 million terabytes of data are generated every single day from 6 billion devices. By 2020, more devices will be connected and it is estimated that nearly 30 million terabytes of data will be generated every day.
In layman’s language Data science is an interdisciplinary field that uses scientific methods, processes, algorithms, and systems to extract knowledge and insights from noisy, structured, and unstructured data, and apply knowledge and actionable insights from data across a broad range of application domains.
And if you wish to start a career as a data scientist, you must be prepared to impress your prospective employers. And to do so you must be able to crack your next data science interview like a rockstar!
Henry Harvin’s Data Science course is one of the most sought-after courses for candidates looking to get in-depth knowledge and prepare for a data science job.
In this article, we have meticulously hand-picked the most commonly asked data science interview questions for both freshers and experienced thus making the interview process a cakewalk for the candidates.
Data Science Interview questions are divided into three categories:
- Basic
- Intermediate
- Advanced

Basic Data Science Interview Questions
1.What is Data Science?
Data Science is a field of computer science that deals with tweaking data into information and extracting meaningful insights out of it. Data science has led to some major innovations in several products and companies. With the data, one can determine the taste of a particular customer, the likelihood of a product succeeding in the market, etc.
2.How is Data Science different from traditional application programming?
|
Data Science |
Traditional programming |
|
Value-based approach |
Traditional approach |
|
|
|
|
Data science algorithms are used to generate rules to map the given inputs to outputs. |
Manual analyzing of input, guessing the expected output, and writing code, which contains rules needed to convert input into output. |
|
|
|
|
Rules are automatically generated or learned from the given data. |
Rules have to write to map the input to the output. |
|
|
|
|
Helps solve difficult challenges with ease. |
A lengthy and a tedious process |
3.What do you understand by linear regression?
Linear regression helps in understanding the relationship between the dependent and the independent variables. It is a supervised learning algorithm, where one is the predictor or the independent variable and the other is the response or dependent variable. If there is only one independent variable it is called simple linear regression, and if there is more than one independent variable it is called multiple linear regression.
4.What do you understand by logistic regression?
Logistic regression is a classification algorithm that can be used when the dependent variable is binary. Let’s take an example. If we are trying to determine whether it will rain or not based on temperature and humidity
5.What is a confusion matrix?

The confusion matrix is a table that is used to estimate the performance of a model. A 2*2 formula matrix is used to know the actual and the predicted values.
True positive (d): This denotes all those records where actual values and predicted values both are true.
False Negative (c): This shows that actual values are true and predicted values are false.
False Positive (b): In this the actual values are false and the predicted values are true.
6.What do you understand by true positive rate and false-positive rate?
|
True Positive Rate |
False Positive Rate |
|
Measures the percentage of actual positives, correctly identified |
The ratio between the number of negative events wrongly categorized as positive upon the total number of actual events |
|
|
|
|
Formula: True positive rate= True positives/Positives |
False Positive Rate= False Positives/Negatives |
7.Explain the difference between supervised and unsupervised learning
These are two types of machine learning techniques and are used to solve different kinds of problems.
|
Supervised Learning |
Unsupervised Learning |
|
Works on the data that contains both inputs and the expected output, i.e., the labeled data |
Works on the data that contains no mappings from input to output, i.e., the unlabeled data |
|
| |
|
Used to create models that can be employed to predict or classify things |
Used to extract meaningful information out of large volumes of data |
|
| |
|
Commonly used supervised learning algorithms: linear regression, decision tree, etc. |
Commonly used unsupervised learning algorithms: K- means clustering, apriori algorithm, etc. |
|
|
8.What is dimensionality reduction?
Dimensionality reduction is the process of converting a dataset with a high number of fields to a dataset with a lower number of dimensions. This is done by dropping some fields or columns from the dataset. However, this is not done haphazardly. In this process, the dimensions are dropped only after making sure that the remaining information will still be enough to succinctly describe similar information.
9.What is bias in Data Science?
Bias is a type of error that occurs in a Data Science model because of using an algorithm that is not strong enough to capture the underlying patterns or trends that exist in the data. In other words, this error occurs when the data is too complicated for the algorithm to understand, so it ends up building a model that makes simple assumptions. This leads to lower accuracy because of underfitting. Algorithms that can lead to high bias are linear regression and logistic regression.
10.Why Python is used for Data Science Cleaning in DS?
Data Scientists have to clean and transform the huge data sets in a form that they can work with. It’s is important to deal with the redundant data for better results by removing nonsensical outliers, malformed records, missing values, inconsistent formatting, etc.
Python libraries such as Matplotlib, Pandas, NumPy, Keras, and Scipy are extensively used for Data cleaning and analysis. These Libraries are used to load and clean the data doe effective analysis.
11.What are some of the techniques used for sampling? What is the main advantage of sampling?
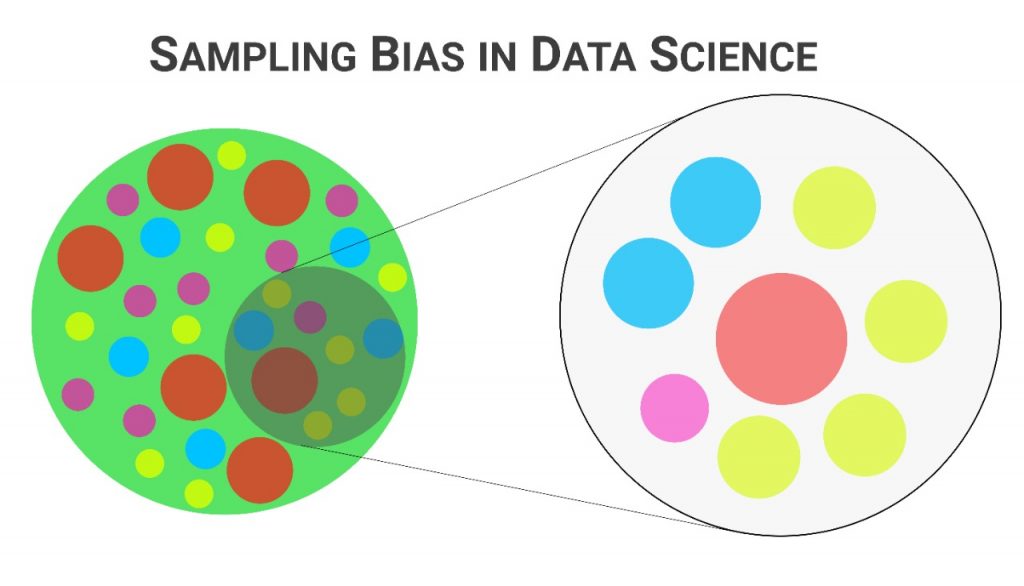
Data analysis cannot be done on a whole volume of data at a time especially when it involves larger datasets. It becomes crucial to take some data samples that can be used for representing the whole population and then perform analysis on it. While doing this, it is very much necessary to carefully take sample data out of the huge data that truly represents the entire dataset.
There are two categories of sampling techniques:
- Probability Sampling Techniques
- Non-probability sampling Techniques
12.List down the conditions for Overfitting and Underfitting.
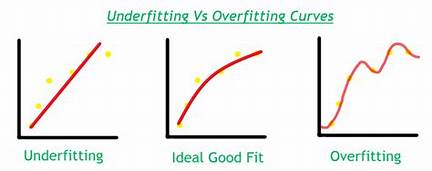
Overfitting: The model performs well only for the sample training data. If any new data is given as input to the model, it fails to provide any result. These conditions occur due to low bias and high variance in the model. Decision trees are more prone to overfitting.
Underfitting: Here, the model is so simple that it is not able to identify the correct relationship in the data, and hence it does not perform well even on the test data.
This happens due to high bias and low variance. Linear regression is more prone to underfitting.
13.Differentiate between the long and wide format data.
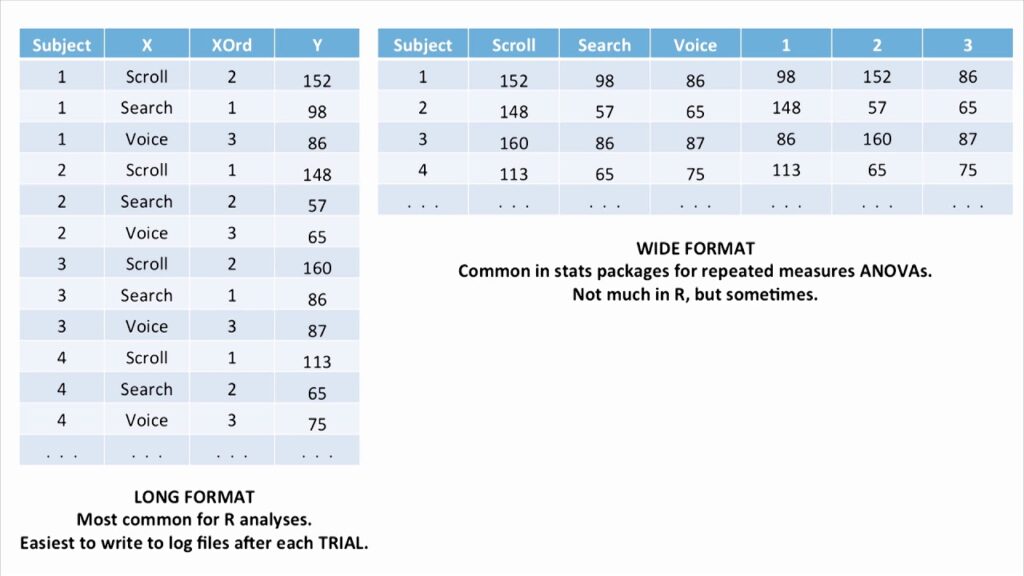
|
Long Format Data |
Wide-Format Data |
|
Here, each row of the data represents the one-time information of a subject. Each subject would have its data in different/multiple rows. |
Here, the repeated responses of a subject are part of separate columns. |
|
|
|
|
The data can be recognized by considering rows as groups. |
The data can be recognized by considering columns as groups. |
|
|
|
|
This data format is most commonly used in R analyses and to write into log files after each trial. |
This data format is rarely used in R analyses and most commonly used in stats packages for repeated measures ANOVAs. |
14.What are Eigenvectors and Eigenvalues?
Eigenvectors are column vectors of unit vectors whose length/magnitude is equal to 1. They are also called right vectors.
Eigenvalues are coefficients that are applied on eigenvectors which give these vectors different values for length or magnitude.
15.What does it mean when the p-values are high and low?
- A low p-value means values 05 mean that the null hypothesis can be rejected and data is unlikely with true null.
- High p-value means 05 indicated the strength in favor of the null hypothesis. It means that the data is like with true null.
- P-value= 0.05 means that the hypothesis can go either way.
16.When is resampling done?
Resampling is a methodology used to sample data for improving accuracy and quantifying the uncertainty of population parameters. It is done to ensure the model is good enough by training the model on different patterns of a dataset to ensure variations are handled. It is also done in the cases where models need to be validated using random sunsets or when substituting labels on data points while performing tests.
17.What do you understand by Imbalanced Data?
Data is said to be highly imbalanced if it is distributed unequally across different categories. These datasets result in an error in model performance and result in inaccuracy.
18.Are there any differences between the expected value and mean value?
There are not many differences between these two, but it is noted that these are used in different contexts. The mean value generally refers to the probability distribution whereas the expected value is referred to random variables.
19.What do you understand by Survivorship Bias?
This bias refers to the logical error while focusing on aspects that survived some process and overlooking those that did not work due to lack of prominence. This bias can lead to deriving wrong conclusions.
20.Define the terms KPI, Lift, model fitting, robustness, and DOE.
- KPI: Stands for Key Performance Indicator that measures how well the business achieves its objectives.
- Lift: This is a performance measure of the target model measured against a random choice model. Lift indicates how good the model is at prediction versus if there was no model.
- Robustness: This represents the system’s capability to handle differences and variances effectively.
- DOE: Stands for the design of experiments, which represents the task design aiming to describe and explain information variation under hypothesized conditions to reflect variables.
Intermediate level Data Science Questions.
21.How are the time series problems different from other regression problems?
- Time series data can be thought of as an extension to linear regression which uses terms like autocorrelation, movement of averages for summarizing historical data of y-axis variables for predicting a better future.
- Forecasting and prediction is the main goal of time series problems where accurate predictions can be made but sometimes the underlying reasons might not be known.
- Having Time in the problem does not necessarily mean it becomes a time series problem. There should be a relationship between target and time for a problem to become a time series problem.
- The observation close to one another in time are expected to be similar to the ones far away which provide accountability for seasonality. For instance, today’s weather but not similar from 4 months from today. Hence, weather prediction based on past data becomes a time series problem.
22.Suppose there is a dataset having variables with missing values of more than 30%, how will you deal with such a dataset?
Depending on the size of the dataset, we follow the below ways:
- In case the dataset is small, the missing values are substituted with the mean or average of the remaining data. In pandas, this can be done by using mean= df. mean() where df represents the panda’s data frame representing the dataset and mean() calculates the mean of the data. To substitute the missing values with the calculated mean, we can use df. fill (mean).
- For larger datasets, the rows with missing values can be removed and the remaining data can be used for data production.
23.What is Cross-Validation?
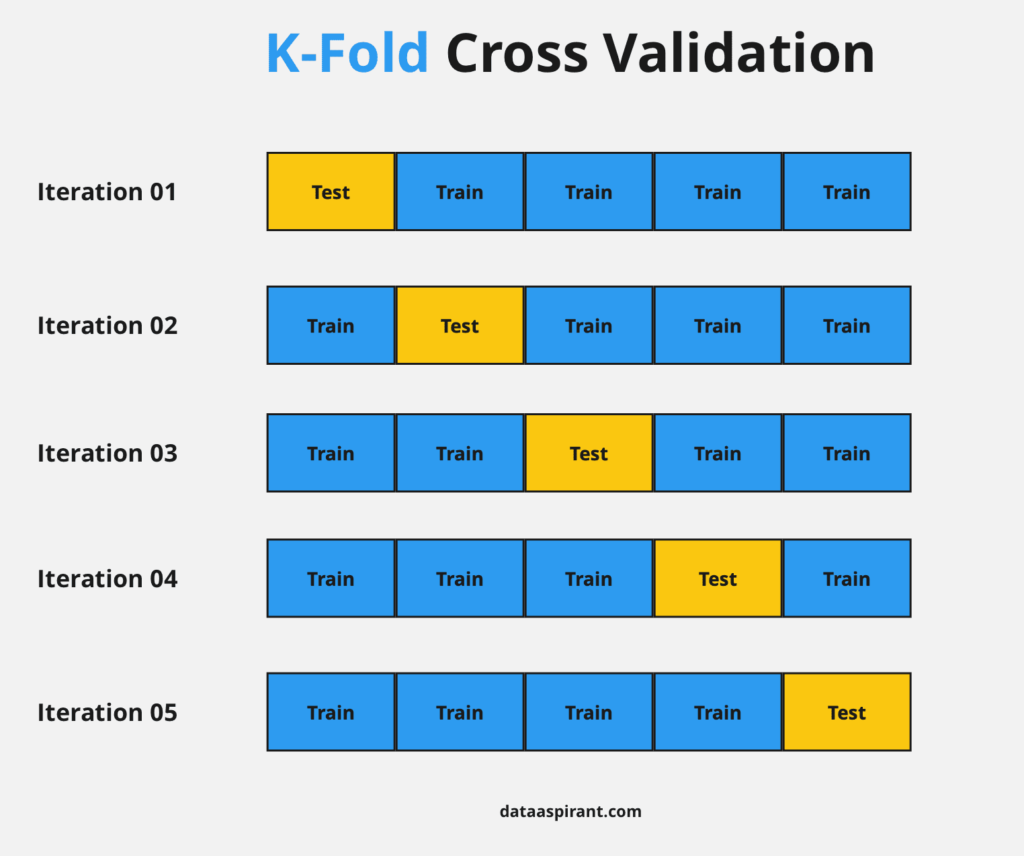
Cross-Validation is a statistical technique used for improving a model’s performance. Here, the model will be trained and tested with rotation using different samples of the training dataset to ensure that the model performs well for unknown data. The training data will be split into various groups and the model is run and validated against these groups in rotation.
The most commonly used techniques are:
- K- Fold method
- Leave pout method
- Leave-one-out method
- Holdout method
24.What are the differences between correlation and covariance?
|
Correlation |
Covariance |
|
This technique is used to measure and estimate the quantitative relationship between two variables and is measured in terms of how strong are the variables related. |
It represents the extent to which the variables change together in a cycle. This explains the systematic relationship between pair of variables where changes in one affect changes in another variable. |
|
|
|
Mathematically, consider 2 random variables, X and Y where the means are represented as:
detect Hand”: False and
and standard deviations are represented by
respectively and E represents the expected value operator, then:
- Covariance XY=E[(X-
- CorrelationXY = E[(X-
So that
Correlation (X, Y) = covariance (X, Y)/(covariance (X) covariance (Y))
25.How do you approach solving any data analytics-based project?
Generally, we follow the below steps:
- The first step is to thoroughly understand the business requirement
- Next, explore the given data and analyze it carefully. If you find any data missing, get the requirements clarified from the business.
- Data cleanup and preparation step is performed. Here, the missing values are found and the variables are transformed.
- Run your model against the data, build meaningful visualization and analyze the results to get meaningful insights
- Release the model implementation, track the results and performance over a specified period to analyze the usefulness
- Perform cross-validation of the model.
26.Why do we need selection Bias?
Selection bias happens in cases where there is no randomization specifically achieved while picking a part of the dataset for analysis. This bias tells that the sample analyzed does not represent the whole population meant to be analyzed.
27.Why is data cleaning crucial? How do you clean the data?
- Data cleaning of the data coming from different sources helps in data transformation and results in the data where the data scientists can work on.
- Properly cleaned data increases the accuracy of the model and provides very good predictions.
- If the dataset is very large, then it becomes cumbersome to run data on it. The data cleanup step takes a lot of time (around 80%) if the data is huge. Hence, cleaning data before running the model, results in increased speed and efficiency of the model.
- Data cleaning helps to identify and fix any structural issues in the data. It also helps in removing any duplicates and maintains the consistency of the data.
The following diagram represents the advantages of data cleaning:
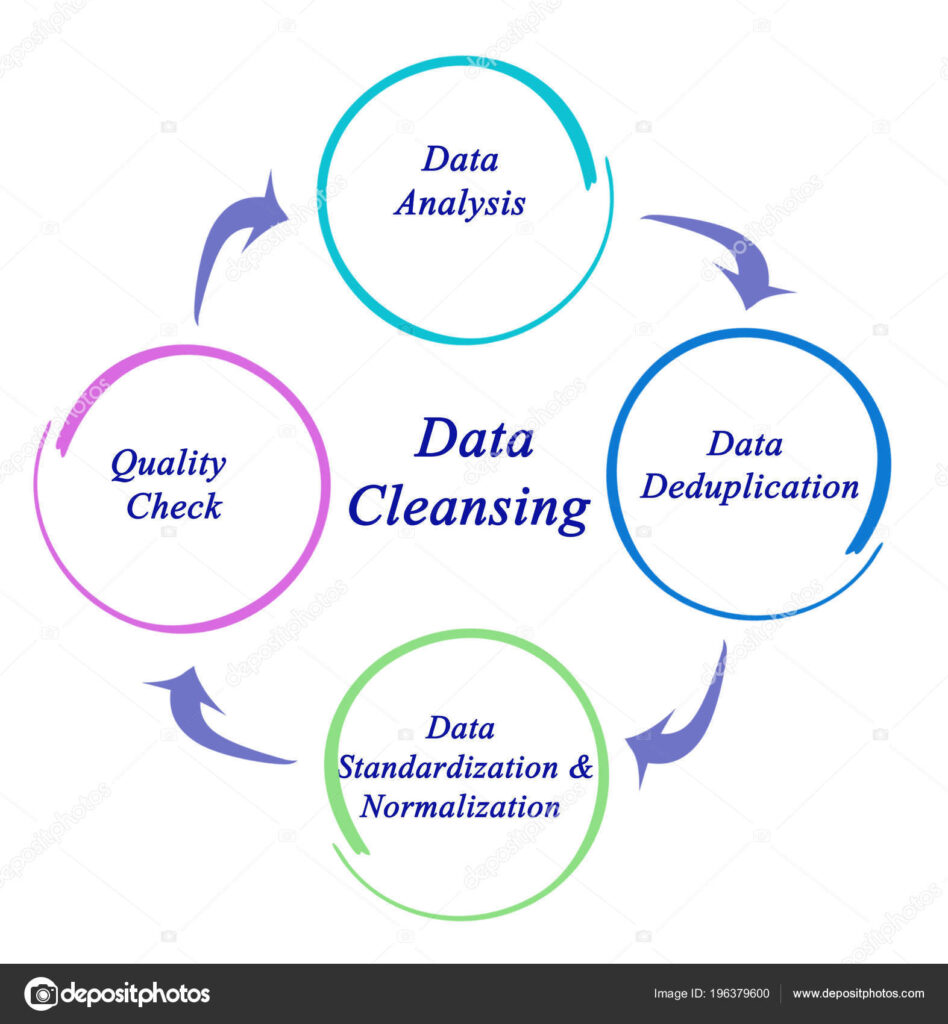
28.What are the available feature selection methods for selecting the right variables for building efficient predictive models?
These methods pick up only the intrinsic properties of features that are measured via univariate statistics and not cross-validated performance.
There are various filter methods such as the Chi-Square test, Fisher’s Score method, Correlation Coefficient, Variance Threshold, Mean Absolute Difference(MAD) method, Dispersion Ratios, etc.
Filter Method
- Wrapper Methods
These methods need some sort of method to search greedily on all possible feature subsets, access their quality by learning and evaluating a classifier with the feature.
There are three types of wrapper methods:
- Forward selection
- Backward selection
- Recursive feature Elimination
Embedded Methods:
It has the benefits of both filter and wrapper methods by including feature interactions while maintaining reasonable computational costs.
Examples of embedded methods: LASSO Regularization(L1), Random Forest Importance.
29.Will treating categorical variables as continuous variables result in a better predictive model?
Yes! A categorical variable is a variable that can be assigned to two or more categories with no definite category ordering. Ordinal variables are similar to categorical variables with proper and clear ordering defines. So, If the variable is ordinal, then treating the categorical value as a continuous will result in better predictive models.
30.How will you treat missing values during data analysis?
The impact of missing values can be known after identifying what kind of variables have the missing values.
- If the data analyst finds any pattern in these missing values, then there are chances of finding meaningful insights.
- In case of patterns are not found, then these missing values can be either ignored or can be replaced with default values such as mean, minimum, maximum, or median values.
- If 80% values are missing, then it depends on the analyst to either replace them with default values or drop the variables.
Data science Questions Advanced level
31.What is the difference between the Test set and the Validation set?
The test set is used to test or evaluate the performance of the trained model. It evaluates the prediction power of the model.
The Validation set is part of the training set that is used to select parameters for avoiding model overfitting.
32.What are the differences between univariate, bivariate, and multivariate analysis?
|
Univariate analysis |
Bivariate analysis |
Multivariate analysis |
|
This analysis deals with solving only one variable at a time. |
It solves two variables at a given time. |
It solves more than two variables at a time. |
|
|
|
|
|
Example: Sales pie charts based on territory. |
Example: scatterplot of sales and spend volume analysis study |
Example: Study of the relationship between human’s social media habits and their self-esteem which depends on multiple factors like age, number of hours spent, employment status, relationship status, etc. |
33.What do you understand by a kernel trick?
Kernel functions are generalized dot product functions used for the computing dot product of vectors xx and yy in high dimensional feature space. The kernel trick method is used for solving a non-linear problem by using a linear classifier by transforming linearly inseparable data into separable ones in higher dimensions.
34.Differentiate between box plot and histogram.
Box plots and histograms are both visualizations used for showing data distributions for efficient communication of information.
Histograms are the bar chart representation of information that represents the frequency of numerical variable values that are useful in estimating probability distribution, variations, and outliers.
Boxplots are used for communicating different aspects of data distribution where the shape of the distribution is not seen but still the insights can be gathered. These are useful for comparing multiple charts at the same time as they take less space when compared to histograms.
35.How will you balance/correct imbalanced data?
There are different techniques to correct imbalanced data. It can be done by increasing the sample numbers for minority classes. The number of samples can be decreased for those classes with extremely high data points. Following are some approaches followed to balance data:
- Use the right evaluation metrics
- Specificity/Precision
- Sensitivity
- F1 score
- MCC( Mattews correlation coefficient)
- AUC( Area Under the Curve)
36.What is better- random forest or multiple decision trees?
Random forest is better than multiple decision trees as random forests are much more robust, accurate, and lesser prone to overfitting as it is an ensemble method that ensures multiple weak decision trees learn strongly.
37.Consider a case where you know the probability of finding at least one shooting star in a 15-minute interval is 30%. Evaluate the probability of finding at least one shooting star in a one-hour duration?
We know that,
Probability of finding atleast 1 shooting star in 15 min= P (sighting in 15min) = 30%= 0.3
Hence, Probability of not sighting any shooting star in 15min = 1-P (sighting in 15min)
=1-0.3
=0.7
Probability of not finding a shooting star in 1 hour
=0.7^4
=0.1372
Probability of finding at least 1 shooting star in 1 hour = 1-0.1372
=0.8628
So the probability is 0.8628=86.28%
38.Toss the selected coin 10 times from a jar of 1000 coins. Out of 1000 coins, 999 coins are fair and 1 coin is double-headed, assume that you see 10 heads. Estimate the probability of getting in the next coin toss.
Using Bayes rule,
So, the answer is 0.7531 or 75.3%
39.What are some examples when false positive has proven important than false negative?
Some examples where false positives were important than false negatives are:
- In the medical field: Consider that a lab report has predicted cancer to a patient even if he did not have cancer. This is an example of a false positive error. It is dangerous to start chemotherapy for that patient doesn’t have cancer and would lead to damage of healthy cells and might even actually cause cancer.
40.Give one example where both false positives and false negatives are important equally?
In banking fields: lending loans are the main sources of income to the banks. But if the repayment rate isn’t good, then there is a risk of huge losses instead of profits. So giving out loans to customers is a gamble as banks can’t risk losing good customers but at the same time, they can’t afford to acquire bad customers. This case is a classic example of equal importance in false positive and false negative scenarios.
41.Is it good to dimensionality reduction before fitting a support Vector Model?
If the features number is greater than observations then doing dimensionality reduction improves the SVM (Support Vector Model).
42.What are various assumptions used in linear regression? What would happen if they are violated?
Linear regression is done under the following assumptions:
- The sample data used for modeling represents the entire population
- There exists a linear relationship between the X-axis variable and the mean of the Y variable
- The residual variance is the same for any X values. This is called homoscedasticity.
- The observation is independent of one another
- Y is distributed normally for any value of X
43.How is feature selection performed using the regularization method?
The method of regularization entails the addition of penalties to different parameters in the machine learning model to avoid the issue of overfitting.
44.How do you identify if a coin is biased?
To identify this, we perform a hypothesis test as below:
- Flip coin 500 times
- Calculate p-value.
- Compare the p-value against the alpha-> result of the two-tailed test (0.05/2=0.025).
Following two cases might occur:
p-value>alpha: Then null hypothesis holds good and the coin is unbiased
p-value<alpha: Then the null hypothesis is rejected and the coin is biased.
45.We want to predict the probability of death from heart disease on three risk factors:
Choose the correct option:
- Logistic Regression
- Linear Regression
- K- means clustering
- Apriori algorithm
The most appropriate algorithm for this case is A, logical regression.
46.What are the drawbacks of a linear model?
- The assumption of linearity of the errors
- It can’t be used for count outcomes or binary outcomes
- There are overfitting problems that it can’t solve.
47.What is the law of large numbers?
It is a theorem that describes the result of performing the same experiment very frequently. This theorem forms the basis of frequency-style thinking. It states that the sample mean, sample variance, and sample standard deviation converge to what they are trying to estimate.
48.What are the confounding variables?
These are extraneous variables in a statistical model that correlates directly or inversely with both the dependent and the independent variable. The estimate fails to account for the confounding factor.
49.What are the types of biases that can occur during sampling?
- Selection bias
- Undercoverage bias
- Survivorship bias
50.How do you work toward a random forest?
- Build several decision trees on bootstrapped training samples of data
- On each tree, each time a split is considered, a random sample of mm predictors is chosen as split candidates out of all pp predictors
- Rule of thumb: At each split m=p^m=p
- Predictions: At the majority rule
Conclusion
This exhaustive list is sure to strengthen your preparation for data science interview questions.









")

{kind=link}
This article provides an excellent compilation of data science interview questions and answers. It covers a wide range of topics, ensuring that candidates are well-prepared for their interviews. The explanations are clear and concise, making it a valuable resource for anyone aspiring to excel in data science.
I found this article on data science interview questions extremely helpful. It offers well-explained answers and covers various aspects of the field. It’s a great resource for both beginners and experienced professionals in the data science industry.
This article on data science interview questions and answers is a comprehensive resource! It covers a wide range of topics, providing valuable insights for anyone preparing for their next data science interview. A must-read for aspiring data scientists.
This website offers a comprehensive collection of Data Science interview questions and answers, providing valuable resources for professionals preparing for interviews in the field.
As a working professional, I have only a small amount of time left to search for a good place to describe data science institute. But this blog post really saved me from my troubles. Happy to see some quality content like this on the website. and I learned a lot from Data Science Question for Interview. Great share.
I was stressed out in finding the right place to do the Data science interview Question and now with the help of this blog post, I am glad I found the right place to do it. Really impressive and I learned a lot from Data Science Question for Interview. Great share.
I want to thank the writers for taking the effort and making a write up on the Data Science Interview Q/A. This is a great way to know a different perspective on this topic. It is great to know so much about Data Science. Thank you for this share. It is for sure relevant and helpful for everyone interested.
As a working professional, I have only a small amount of time left to search for a good place to describe data science institute. But this blog post really saved me from my troubles. Happy to see some quality content like this on the website. Really an amazing write up on the data science interview questions.
This is the best way for anyone to find the right place to do the top 50 data science interview questions and answers for 2022 as the article really is organized and easier to crack for interview. Thank you.
It has been a while since I have seen a write up as useful as this one right here. This really gives out the necessary facts on the topic of the data science interview question and answers. Thank you for this share.